
- Date


In this article I want to dive into the current state of Gutenberg and WPGraphQL.
This is a technical article about using Gutenberg blocks in the context of decoupled / headless / API-driven WordPress, and makes the assumption that you already know what Gutenberg is and have some general understanding of how it works.
TL;DR
Client-server contracts around the shape of data is fundamental to achieving “separation of concerns”, a pillar of modular and decoupled application development.
While much of WordPress was built with decoupling in mind, the WP REST API and Gutenberg were not.
As a result, decoupled application developers interacting with WordPress are limited in what they can achieve.
With the growing demand for headless WordPress, this is a key limitation that will hamper growth.
Fortunately, even with the limitations, there are ways forward. In this article I walk through 3 approaches you can implement to use Gutenberg in decoupled applications today, tradeoffs included, and propose a plan to make the future of Gutenberg for decoupled applications a better one.
Replacing my door lock
I recently replaced the lock on the front door of my house.
I ordered the lock from an online retailer. I was able to select a specific brand of lock in a specific color.
When the lock arrived and I opened the package, it was the same brand and color that I ordered. It wasn’t just any random lock, it was the one that I agreed to pay for, and the online retailer agreed to mail me.
I was able install the lock without any surprises. I didn’t have to drill any new holes in my door. The new lock fit the hole in my door that I removed the old lock from.
The new lock wasn’t made by the same manufacturer that made the door, and yet, the lock installed on my door just fine. In fact, there were at least 30 different locks from a variety of manufacturers that I could have selected that all would have worked in my door without any complications.
Decoupled systems
This wasn’t really a story about doors and locks. It’s a story about decoupled systems, and the contracts, or agreements, that make them work.
And its intent is to help frame what I’m talking about with using WordPress, and specifically Gutenberg, in decoupled contexts.
In order for decoupled systems to work well, whether it’s doors and door locks, or WordPress and a decoupled JavaScript application, there needs to be some sort of agreement between the different parts of the system.
In the case of door and lock manufacturers, it’s an agreement over the size and positioning of the holes in the door.
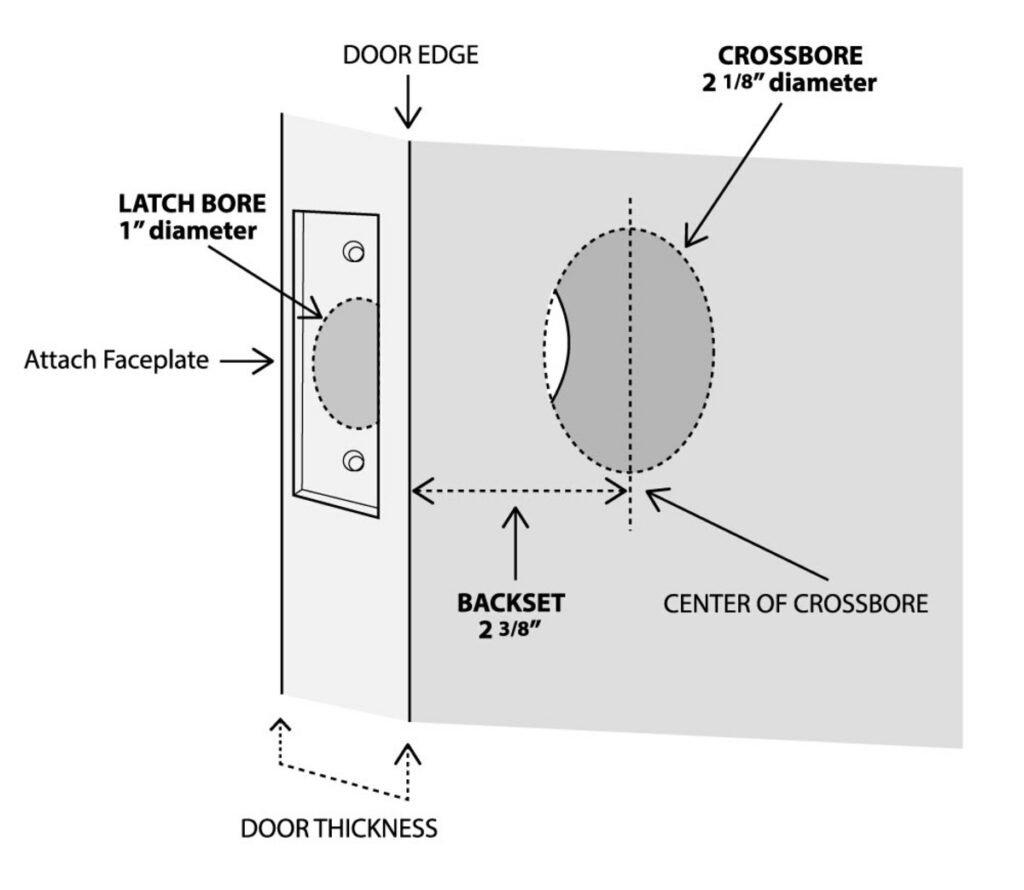
Door manufacturers can build doors at their leisure and lock manufacturers at theirs, and when the time comes to bring them together, they work without issue because both parties are adhering to an agreement.
In the case of e-commerce, there are agreements about what a consumer purchases and what should be delivered. In my case, the online store provided a list of locks that were available to purchase. I selected a specific lock, paid for it, and in response I received the lock we agreed to, in exchange for my payment.
Decoupled tech, decoupled teams
When WPGraphQL first started, I was working at a newspaper that had a CMS team that focused on WordPress, a Native Mobile team that focused on the iOS and Android applications, a Data Warehouse team that collected various data from the organization and a Print team that took the data from WordPress and prepared it for Print.
WordPress was the entry point for content creators to write content, but the web was only one of many channels where content was being used.
Not only was the technology decoupled (PHP for the CMS, React Native for mobile apps, Python for Data warehousing and some legacy system I forget the name of for print), but the teams were also decoupled.
The only team that really needed to understand WordPress was the CMS team. The other teams were able to use WPGraphQL Schema Introspection to build tools for their teams using data from WordPress, without needing to understand anything about PHP or WordPress under the hood.
Much like door and lock manufacturers don’t need to be experts at what the other is building, WPGraphQL’s schema served as the contract, enabling many different teams to use WordPress data when, and how, they needed.
WPGraphQL served as the contract between the CMS team and the other teams as well as WordPress the system and the other team’s decoupled systems.
WordPress contracts
For WordPress, one of the common contracts, or agreements established between multiple systems (such as plugins, themes, and WordPress core) comes in the form of registries.
WordPress has registries for Post Types, Taxonomies, Settings, Meta and more.
The register_post_type function has more than 30 options that can be configured to define the contract between the Post Type existing and how WordPress core and decoupled systems (namely plugins and themes) should interact with it.
The register_taxonomy, register_meta, register_setting, register_sidebar and other register_* functions in WordPress serve a similar purpose. They allow for a contract to be established so that many different systems can work with WordPress in an agreed upon way.
These registries serve as a contract between WordPress core and decoupled systems (themes and plugins) that can work with WordPress. Because these registries establish an agreement with how WordPress core will behave, plugins and themes can latch onto these registries and extend WordPress core in some powerful ways.
The decoupled (pluggable) architecture of WordPress is enabled by these contracts.

Registering a new post type to WordPress can get you a UI in the WordPress dashboard, but it can also get your content indexed to Elastic Search via ElasticPress, powerful SEO tools from WordPress SEO, custom admin functionality from Advanced Custom Fields, and API access via WPGraphQL.
If the next release of WordPress started hiding the UI for all post types that were registered with show_ui => true, or stopped allowing plugins from reading the post type registry, there would likely be a bug (or hundreds) reported on Trac, (and Twitter, and Slack, etc), as that would mean WordPress was breaking the established contract.
The client/server contract
Like we discussed earlier, decoupled systems need some sort of shared agreement in order to work well together. It doesn’t have to be a GraphQL API, but it has to be something.
For WordPress, this comes in the form of APIs.
WordPress core has 2 built-in APIs that enable decoupled applications to interact with WordPress data, XML-RPC and the WP REST API.
And, of course, there’s yours truly, WPGraphQL, a free open-source WordPress plugin that provides an extendable GraphQL schema and API for any WordPress site.
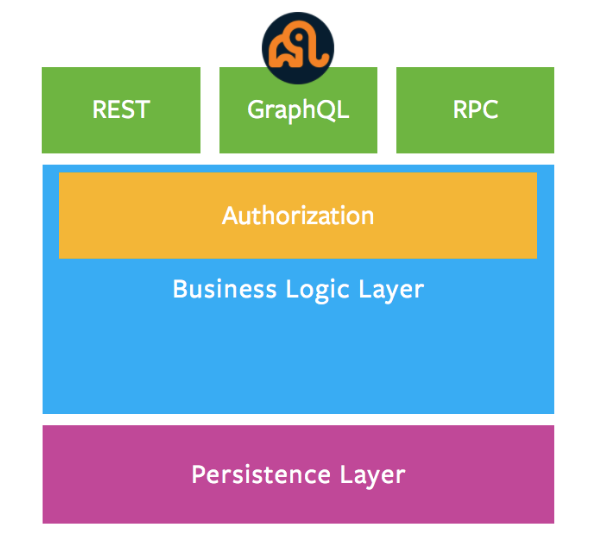
In order for decoupled applications, such as Gatsby, NextJS, Frontity, native mobile applications or others, to work with WordPress, the APIs must establish a contract that WordPress and the decoupled application can both work against.
The WP REST API provides a Schema
The WordPress REST API provides a Schema that acts as this contract. The Schema is introspect-able, allowing remote systems to see what’s available before asking for the data.
This is a good thing!
But the Schema is not enforced
However, the WP REST API doesn’t enforce the Schema.
WordPress plugins that extend the WP REST API Schema can add fields to the API without defining what data will be returned in the REST API Schema. Or, they can register fields that return “object” as a wildcard catch-all.
This is a bad thing!
Decoupled teams and applications cannot reliably use the WordPress REST API if it doesn’t enforce any type of contract.
Optional Schema and wildcard return types
Plugins such as the Advanced Custom Fields to REST API add a single “acf” field to the REST endpoints and declare in the WP REST API that the field will return “an object”.
We can see this if we introspect the WP REST API of a WordPress install with this plugin active:

This means that decoupled applications, and the teams building them, have no way to predict what data this field will ever return. This also means that even if a decoupled application does manage to get built, it could break at any time, because there’s no contract agreed to between the client and the server. The WordPress server can return anything at anytime.
Unpredictable data is frustrating for API consumers
With the field defined as “object” the data returned can be different from page to page, post to post, user to user, and so on. There’s no predictable way decoupled application developers can prepare for the data the API will return.
This would be like me trying to purchase that door lock, but instead of the website showing me a list of door locks with specific colors to chose from, I was just given one “product” as the option to purchase.
The “product” might be a hat or some new sunglasses, or if I’m really lucky, it might be a door lock. I don’t have any way of knowing what the “product” is, until I receive it.
As an e-commerce consumer, this is not helpful.
And as a decoupled application developer, this type of API is frustrating.
Decoupled systems don’t work well if part of the equation is to “just guess”.
GraphQL enforces Schema and Strong Types
WPGraphQL, on the other hand, enforces a strongly Typed Schema. There is no option to extend the WPGraphQL API without describing the type of data the API will return. Additionally, there is no “wildcard” type.
A plugin cannot register a field to the WPGraphQL Schema that returns a door lock on one request, and sunglasses or a hat on the next request.
To extend WPGraphQL, plugins must register fields that declare a specific Type of data that will be returned. And this contract must be upheld.
This removes the “just guess” part of the equation.
Decoupled application developers always know what to expect.
Much like I, as an e-commerce consumer, was able to browse the list of door locks that were possible to purchase on the online store, decoupled application developers can use a tool such as GraphiQL to browse the GraphQL Schema and see what Types and Fields are available to query from the GraphQL API.
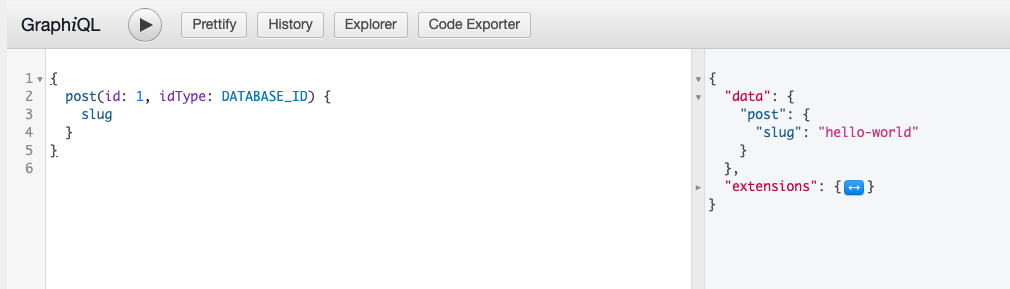
The screenshot below shows GraphiQL being used to explore a GraphQL Schema. The screenshot shows the type named “Post” in the GraphQL Schema with a field named “slug” which declares that it will return a String.

Application developers can take the information they get from the Schema and construct queries that are now predictable.
And the GraphQL Schema serves as the contract between the server and the client application, ensuring that the server will return the data in the same shape the client was promised.
Just like I received the specific door lock matching the brand and color that I specified in my order, client applications can specify the Types and Fields they require with a GraphQL Query, and the response will match what was asked for.
In the example below, the GraphQL Query asks for a Post and the “slug” field, which we can see in the Schema that it will return a String. And in response to this query, the GraphQL server will provide just what was asked for.
The “just guess” part of the server/client equation is eliminated.
Example GraphQL Query & Response
query {
post( id: 1, idType: DATABASE_ID ) {
slug
}
}{
"data": {
"post": {
"slug": "hello-world",
},
},
}
The Gutenberg block registry
Now that we’re on the same page about contracts between decoupled systems and how WPGraphQL provides a contract between the WordPress server and client applications, let’s move on to discuss Gutenberg more specifically.
Early integration with WPGraphQL
Gutenberg as a concept was fascinating to me early on. Like many others, I saw the potential for this block-based editor to impact WordPress users and the WordPress ecosystem greatly, WPGraphQL included.
I explored exposing Gutenberg blocks as queryable data in WPGraphQL as far back as June 2017:
Challenges and the current state of Gutenberg
While a basic initial integration was straightforward, I ran into roadblocks quickly.
Gutenberg didn’t have a server-side registry for blocks. At this time, all blocks in Gutenberg were fully registered in JavaScript, which is not executed or understood by the WordPress server.
This means that unlike Post Types, Taxonomies, Meta, Sidebars, Settings, and other constructs that make up WordPress, Gutenberg blocks don’t adhere to any type of contract with the WordPress server.
This means that the WordPress server knows nothing about blocks. There are no agreements between Gutenberg blocks and other systems in WordPress, or systems trying to interact with WordPress via APIs.
Blocks were practically non-existent as far as the application layer of WordPress was concerned.
There were no WP-CLI commands to create, update, delete or list blocks. No WP REST API Schema or endpoints for blocks. No XML-RPC methods for blocks. And no way to expose blocks to WPGraphQL.
Without any kind of agreement between the WordPress server and the Gutenberg JavaScript application, the WordPress server can’t interact with blocks in meaningful ways.
For example, the WordPress server cannot validate user input on Gutenberg blocks. Data that users input into the fields in Gutenberg blocks is trusted without question and saved to the database without the server having final say. This is a dangerous precedent, especially as Gutenberg is moving outside of editing Post content and into other parts of full-site editing. As far as I know, the lack of block input validation by the WordPress server is still a problem today.
Anyway, without the WordPress server having any knowledge of blocks, WPGraphQL also could not provide a meaningful integration with Gutenberg.
I was sad, because I was optimistic that this integration could lead to some really great innovations for decoupled applications.
Shortly after my tweet above and running into roadblocks, I raised these concerns with the Gutenberg team on Twitter and Slack. The Gutenberg team asked me to post my thoughts in a Gutenberg Github issue, which I did at length. While my comments received a lot of positive emoji reactions from the community. Unfortunately the issue has been closed with many of the concerns outstanding.
Months later I also voiced similar concerns on the Make WordPress post about Gutenberg and Mobile, pointing out that without a proper server registry and API, decoupled applications, such as the WordPress native mobile application, won’t be able to support Custom Blocks, or even per-site adjustments to core blocks.
As of today, my understanding is that the WordPress native mobile applications still do not support custom blocks or adjustments to core blocks, making the App nearly useless for sites that have adopted Gutenberg.
Even with the limitations of Gutenberg, the headless WordPress community has been determined to use Gutenberg with decoupled applications.
Three approaches to using Gutenberg in decoupled applications, today
Below are some of the different approaches, including tradeoffs, that you can implement today to start using Gutenberg in decoupled applications.
Gutenberg blocks as HTML
I believe the fastest way to get started using Gutenberg in decoupled applications today, is to query the “content” field from WPGraphQL (or the WP REST API, if it’s still your flavor).
This is the approach that Frontity is using.
This is also the approach I’m using for WPGraphQL.com, which is in use on this very blog post you’re reading right now.
This post is written in Gutenberg, queried by Gatsby using WPGraphQL, and rendered using React components!
Here’s how it works (and please don’t judge my hacky JavaScript skills ????):
- The GraphQL Query in Gatsby gets the content (see the code)
- The content is passed through a parser (see the code)
- The parser converts standard HTML elements into the Chakra UI equivalent to play nice with theming (see the code)
- The parser also converts things like HTML for Twitter embeds, and `<code>` blocks into React components (see the code)
- This is how we get neat things like the Syntax highlighting and “copy” button on the code snippets
Tradeoff: Lack of Introspection, unpredictable data
While this is working for me and WPGraphQL.com, I can’t recommend it for everyone.
Using HTML as the API defeats much of the purpose of decoupled systems. In order to use the markup as an API, the developers of the decoupled application need to be able to predict all the markup that might come out of the editor.
Querying HTML and trying to predict all the markup to parse is like me ordering “product” at the store. At any time I (or other users of WordPress) could add blocks with markup that my parser doesn’t recognize and the consuming application might not work as intended.
Tradeoff: Missing data
Content creators can modify attributes of blocks, and Gutenberg saves these attributes as HTML comments in the post_content. But when the content is prepared for public use in WordPress themes, the WP REST API or WPGraphQL, the raw block attributes are not available, so a parser like the one I described will not have all the block data to work with.
Tradeoff: Undefined Types
To overcome the “missing data” issue, it’s possible to pass attributes from Gutenberg blocks as HTML data-attributes in the render_callback for blocks, as a way to get Gutenberg attributes passed from the editor to the rendered HTML and available for a parser to use, but even doing this leads to client applications not knowing what to expect, and leads to undefined Types as all data-attributes are strings, so mapping data-attributes to something like a React or Vue component is difficult and fragile with this method.
When to use
This approach works for me, because I personally control both sides of wpgraphql.com, what blocks are available in the WordPress install, what content is published, and the Gatsby consumer application that queries the content and renders the site. In the e-commerce analogy, I’m both the person ordering the “product” and the person fulfilling the order, so there are no surprises. I’m not working with different teams, or even different team members, and I’m the primary content creator.
For projects that have multiple team members, multiple authors, multiple teams and/or multi-channel distribution of content, I would not recommend this approach. And multi-team, I would argue, includes the team that builds the project, and the team that maintains it after it’s live, which in many agencies are different teams.
Gutenberg Object Plugin
In late 2018, Roy Sivan, a Senior JavaScript Engineer and recurring Happy Birthday wisher to Ben Meredith, released a plugin that exposed Gutenberg blocks to the WP REST API:
This plugin exposes Gutenberg block data to the WP REST API so that data saved to pages can be consumed as JSON objects.
Exposing Gutenberg data as JSON is what a lot of developers building decoupled applications want. They want to take the data in a structured form, and pass the data to React / Vue / Native components. This plugin gets things headed in the right direction!
Tradeoff: Lack of Introspection, unpredictable data
But, because of the lack of a server-side registry for Gutenberg blocks, and the non-enforced Schema of the WP REST API, this plugin also suffers from the “just guess” pattern for decoupled applications.
This plugin is unable to register blocks or fields to the WP REST API, so inspecting the Schema leaves decoupled application developers guessing.
If we Introspect the REST API Schema from this plugin and we can see that the Schema doesn’t provide any information to the decoupled application developer about what to expect.
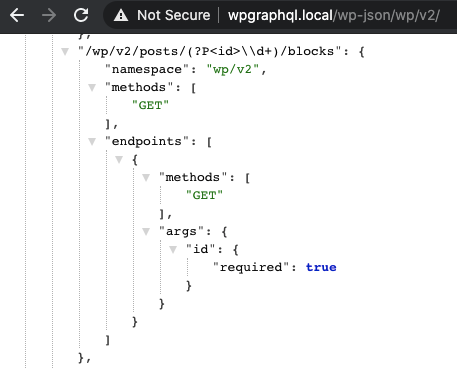
It’s like ordering a “product” from an e-commerce store. The endpoint can return anything at any time, and can change from page to page, request to request.
There’s no contract between the REST endpoints and the consumer application. There’s no scalable way for decoupled application developers to know what type of data the endpoints will return, now or in the future.
Tradeoff: Only available in REST
If you’re building headless applications using WPGraphQL, taking advantages of features that differentiate WPGraphQL from REST, you would not be able to use the GraphQL Objects plugin in your decoupled application without enduring additional pain points, in addition to the lack of introspection.
Caching clients such as Apollo would have to be customized to work with data from these endpoints, and still may not work well with the rest of the application that might be using GraphQL. Additionally, when using REST endpoints with related resources, it becomes the clients responsibility to determine how to map the various block endpoint data to the components that need the data. There’s no concept of coupling GraphQL Query Fragments with Components, like you can do with GraphQL.
When to use:
Again, if you are the developer controlling both sides, the WordPress server and the client application, this approach could work, at least while you’re building the application and the capabilities are fresh in your mind. But in general, this approach can cause some pain points that that might be difficult to identify and fix when things go wrong. For example, 6 months down the road, even the person that built the application will likely forget all the details, and when there’s a bug, and no contract between the applications to refer to, it can be hard to diagnose and fix.
Even when things break with GraphQL applications (and they do), the explicit nature of GraphQL Queries serve as a “documentation of intent” from the original application developer and can make it much easier for teams to diagnose, down to specific leaf fields, what is broken.
WPGraphQL for Gutenberg
In early 2019 Peter Pristas introduced the WPGraphQL for Gutenberg plugin.
The intent of this plugin is to expose Gutenberg blocks to the WPGraphQL Schema, so that decoupled application developers could use tools such as GraphiQL to inspect what blocks were possible to be queried from the API, and compose GraphQL Queries asking for specific fields of specific blocks that they wanted to support.
Now, content creators can publish content with Gutenberg, and decoupled application developers can introspect the Schema and construct queries asking for the specific blocks and fields their application supports.
Decoupled application developers can move at their own pace, independent from the developers and content creators working on the CMS. The decoupled application can specify which blocks are supported, and ask for the exact fields they need. Much like an e-commerce consumer can specify the specific color door lock they want to order from the store! The Schema serves as the contract between the server and the client. Clients can predictably ask for what they want, and get just that in response.
Creating a page
Content creators can use Gutenberg to create pages. In the example blow, we see a page in Gutenberg with a Paragraph block and an Image block.
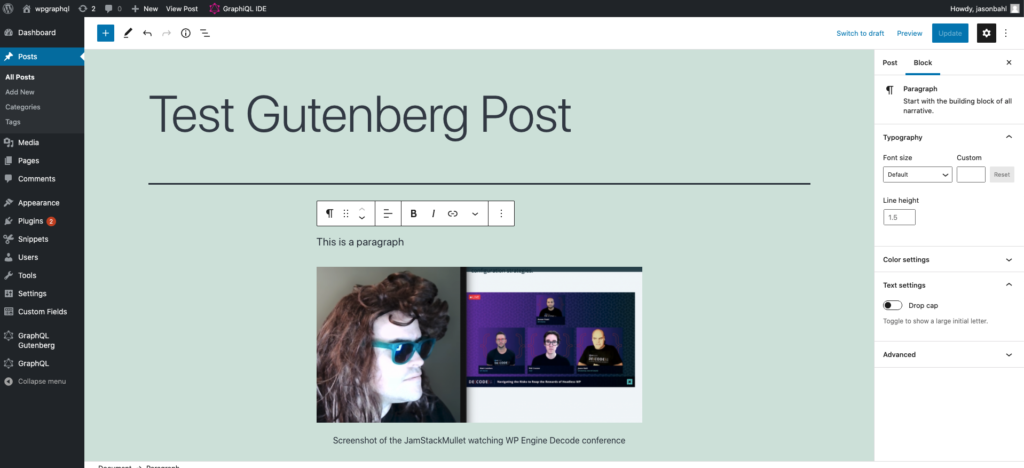
Exploring the Schema
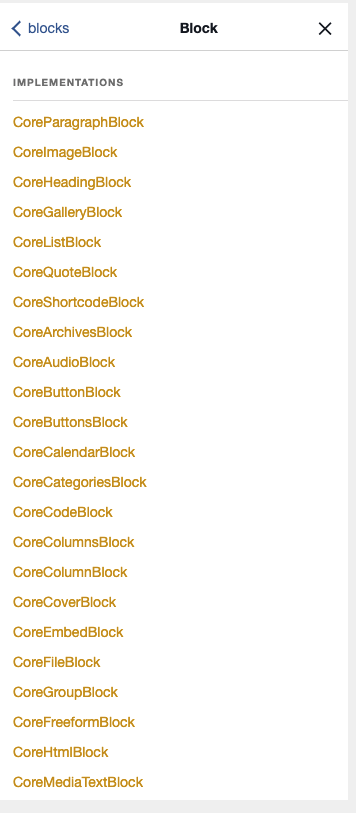
With the plugin installed and activated (for demo sake I have WPGraphQL v1.2.5 and WPGraphQL for Gutenberg v0.3.8 active), decoupled application developers can use GraphiQL to browse the Schema to see what Gutenberg Blocks are available to query and interact with.
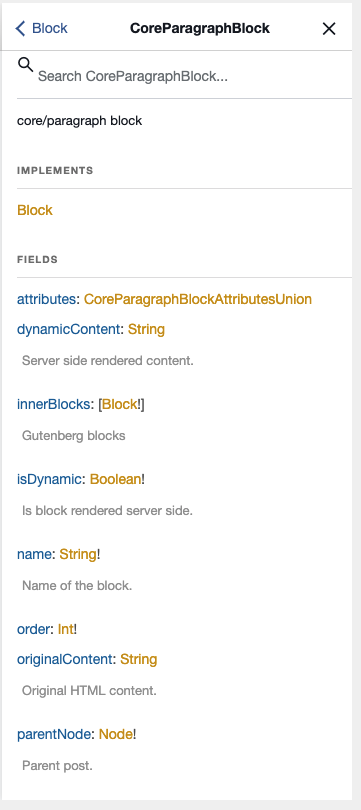
Querying the blocks
And using the Schema, developers can construct a query to ask for the blocks and fields that their application supports.
Here’s an example query:
{
post(id: 6, idType: DATABASE_ID) {
id
databaseId
title
blocks {
__typename
name
... on CoreImageBlock {
attributes {
... on CoreImageBlockAttributes {
url
alt
caption
}
}
}
... on CoreParagraphBlock {
attributes {
... on CoreParagraphBlockAttributes {
content
}
}
}
}
}
}
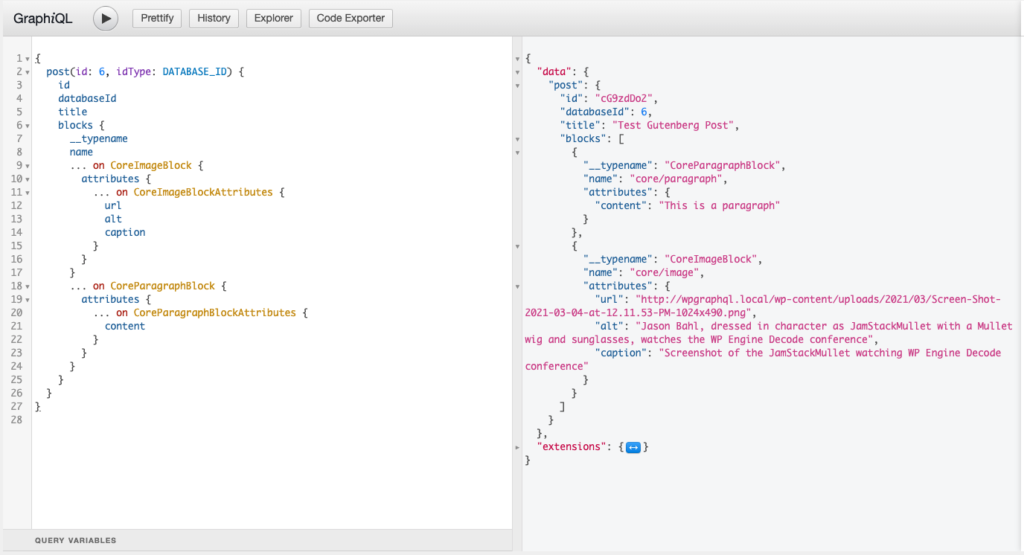
And the response:
You can see that the response includes the exact fields that were asked for. No surprises.
{
"data": {
"post": {
"id": "cG9zdDo2",
"databaseId": 6,
"title": "Test Gutenberg Post",
"blocks": [
{
"__typename": "CoreParagraphBlock",
"name": "core/paragraph",
"attributes": {
"content": "This is a paragraph"
}
},
{
"__typename": "CoreImageBlock",
"name": "core/image",
"attributes": {
"url": "http://wpgraphql.local/wp-content/uploads/2021/03/Screen-Shot-2021-03-04-at-12.11.53-PM-1024x490.png",
"alt": "Jason Bahl, dressed in character as JamStackMullet with a Mullet wig and sunglasses, watches the WP Engine Decode conference",
"caption": "Screenshot of the JamStackMullet watching WP Engine Decode conference"
}
}
}
GraphQL Schema as the contract
Having the GraphQL Schema serve as the contract between the client and server allows each part of the application to move forward at its own pace. There’s now an agreement for how things will behave. If the contract is broken, for example, if the server changed the shape of one of the Types in the GraphQL Schema, it’s easily identifiable and can be fixed quickly, because the client specified exactly what was needed from the server by way of a GraphQL Query.
This removes the “just guess” pattern from decoupled application development with Gutenberg.
Teams that know nothing about WordPress can even make use of the data. For example, a data warehouse team, a native mobile team, a print team, etc. The GraphQL Schema and tooling such as GraphiQL frees up different teams to use the data in their applications how they want.
Client in control
With clients querying Gutenberg blocks as data, this gives clients full control over the presentation of the blocks. Whether the blocks are used in a React or Vue website, or used for a Native iOS app that doesn’t render HTML, or used to prepare a newspaper for print, the client gets to ask for the fields that it needs, and gets to decide what happens with the data. No unexpected changes from the server, the client is in control.
Tradeoffs: Scaling issues
While WPGraphQL for Gutenberg gets us much closer to being able to query Gutenberg blocks as data, it unfortunately has a dependency that makes it very difficult to scale, and it comes back, again, to the lack of a proper server side registry for blocks.
Since Gutenberg Blocks aren’t registered on the server, WPGraphQL for Gutenberg has a settings page where users must click a button to “Update the Block Registry”.

Clicking this button opens up Gutenberg in a hidden iFrame, executes the JavaScript to instantiate Gutenberg, gets the Block Registry from Gutenberg initialized in JavaScript, sends the list of registered blocks to the server and stores the registry in the options table of the WordPress database. The registered blocks that are stored in the database are then used to map to the GraphQL Schema.
Peter Pristas deservers an award, because this approach is a very creative solution to the frustrating problem of Gutenberg not respecting the WordPress server.
Unfortunately this solution doesn’t scale well.
Since Gutenberg blocks are registered in JavaScript, this means that the JavaScript to register any given block might be enqueued from WordPress on only specific pages, specific post types, or other unique individualized criteria.
That means the JavaScript Block Registry for Page A and Page B might be different from each other, and maybe also different from the registry for Post Type C or Post Type D. So loading one page in an iframe to get the block registry might not get the full picture of what blocks are possible to interact with in a decoupled application.
In order for the block registry that is generated from the iframe to be accurate, every page of every post type that Gutenberg is enabled on in the site would need to be loaded by iframe to account for cases where blocks were registered to specific contexts. Yikes!
Tradoffs: Schema design issues
In addition to the scaling issues, there are some concerns with some of the Schema design choices, and I’ll even take the blame for some of this, as I had many conversations with Peter as he worked on the plugin, and he followed my lead with some of my also poor Schema design choices.
One issue is infinite nesting. Gutenberg blocks, as previously discussed, can sometimes have nested inner blocks. In WPGraphQL for Gutenberg, querying inner blocks requires explicit queries and without knowing what level of depth inner blocks might reach, it’s difficult to compose queries that properly return all inner blocks.
WPGraphQL used to expose hierarchical data in a similar way, but has since changed to expose hierarchical data, such as Nav Menu Items, in flat lists. This allows for nested data in any depth to be queried, and re-structured in a hierarchy on the client.
The unlimited depth issue is commonly reported for projects such as Gatsby Source WordPress.
When to use
If Gutenberg is a requirement for your headless project, this might be a good option, as it allows you to query Gutenberg blocks as structured data. You gain a lot of the predictability that you miss with the other options, and can benefit greatly from features of GraphQL such as Batch Queries, coupling Fragments with components, and more.
So while WPGraphQL for Gutenberg is probably the closest option available for being able to predictably query Gutenberg blocks as data in decoupled applications, there are some serious questions in regards to production readiness, especially on larger projects, and you should consider these issues before choosing it for your next project.
Tradeoffs in mind, agencies such as WebDevStudios are using this approach in production, even for large sites.
Progress for the server side block registry
In 2020, some progress was made in regards to a server side registry for Gutenberg blocks.
While the official Gutenberg documentation still shows developers how to create new blocks fully JavaScript with no server awareness, the core Gutenberg blocks have started transitioning to have some data registered on the server.
You can see here that (as of Gutenberg 5.6.2, released in February 2021) core Gutenberg blocks are now registered with JSON files that can be used by the PHP server as well as the JavaScript client.
These JSON files are now used to expose blocks to the WP REST API.
This is progress!
Inner blocks, inner peace?
Unfortunately it’s not all the progress needed to have meaningful impact for decoupled applications to use Gutenberg. There’s a lot of information that a decoupled application would need about blocks that is not described in the server registry. One example (of many) being inner blocks.
Gutenberg has a concept called “Inner Blocks”, which is blocks that can have other blocks nested within. For example, a “Column” block can have other blocks nested within each column, while other blocks such as an Image block cannot have nested inner blocks.
The bit of server side registry that is now available for core Gutenberg blocks doesn’t declare this information. If we take a look at the Column block’s block.json file, we can see there’s no mention of inner blocks being supported. Additionally, if. we look at the Image block’s block.json file, we don’t see any mention of inner blocks not being supported.
In order for a decoupled application, such as the official WordPress iOS app, to know what blocks can or cannot have inner blocks, this information needs to be exposed to an API that the decoupled application can read. Without the server knowing about this information, decoupled applications cannot know this information either.
So, while there’s been a bit of a migration for the core WordPress blocks to have some server (and REST API) awareness, there’s still a lot of missing information. Also the community of 3rd party block developers are still being directed to build blocks entirely in JavaScript, which means that all new blocks will have no server awareness until the server registry becomes more of a 1st-class citizen for Gutenberg.
What’s next?
The beginnings of a move toward a server-side registry gives hope, and gives a bit of a path toward blocks being properly introspect-able and useful by decoupled teams and applications.
Specification for Server Side Registering Blocks
I believe that the step forward for Gutenberg + decoupled applications, is to come up with a specification for how Gutenberg blocks can be registered on the server to work properly with server APIs.
Once a specification is discussed, vetted, tested and published, the WP REST API, WP CLI and WPGraphQL, and therefore decoupled applications such as the WordPress native mobile app, would all make use of the spec to be able to interact with Gutenberg blocks.
I don’t fully know what this spec needs to look like, but I believe it needs to exist in some form.
Projects such as Gutenberg Fields Middleware from rtCamp, ACF Blocks, and Genesis Custom Blocks all take a server-first approach to creating new Gutenberg blocks, and I think there’s a lot to learn from these projects.
The blocks from these tools are created in a way that the WordPress server knows what blocks exist, what attributes and fields the blocks have, and the server can then pass the description of the blocks to the Gutenberg JavaScript application, which then renders the blocks for users to interact with.
Since the server provides the Gutenberg JavaScript application with the information needed to render the blocks to a content producer, this means the server can also provide the information to other clients, such as the native mobile WordPress app, or teams building decoupled front-ends with Gatsby, Gridsome or NextJS.
The future of decoupled Gutenberg
I believe that with a proper specification for registering blocks on the server, Gutenberg can enable some incredibly powerful integrations across the web.
My thoughts are that we can arrive at a specification for registering blocks that can enable block developers to provide pleasant editing experiences, while providing decoupled application developers with the ability to Introspect the GraphQL API, predictably write GraphQL Queries (and Mutations) to interact with blocks, and get predictable, strongly typed results that can be used in decoupled applications.
In an effort to start discussing what the future of a Gutenberg Block Server Registry Specification like this might look like, I’ve opened the following Github issue: https://github.com/wp-graphql/wp-graphql/issues/1764
If this topic interests you, and you’d like to be involved in discussing what such a specification might look like, please contribute ideas to that issue. Additionally, you can Join the WPGraphQL community on Slack community, and visit the #gutenberg channel and discuss in there.